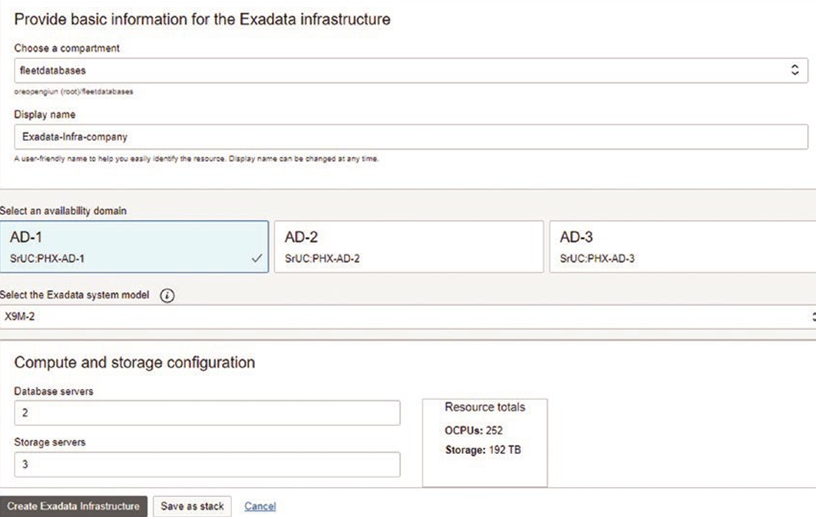
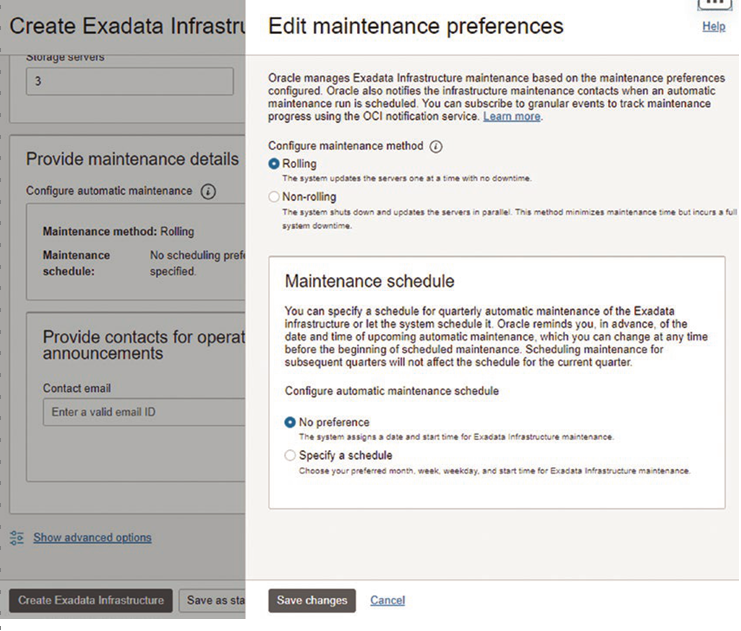
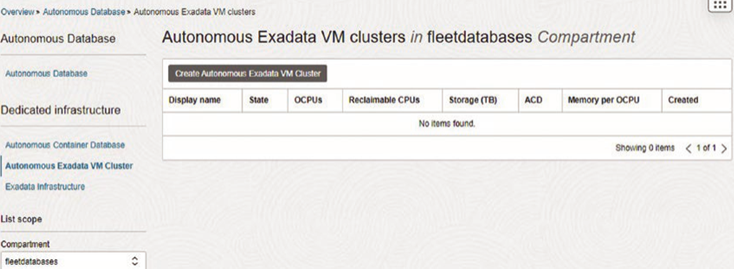
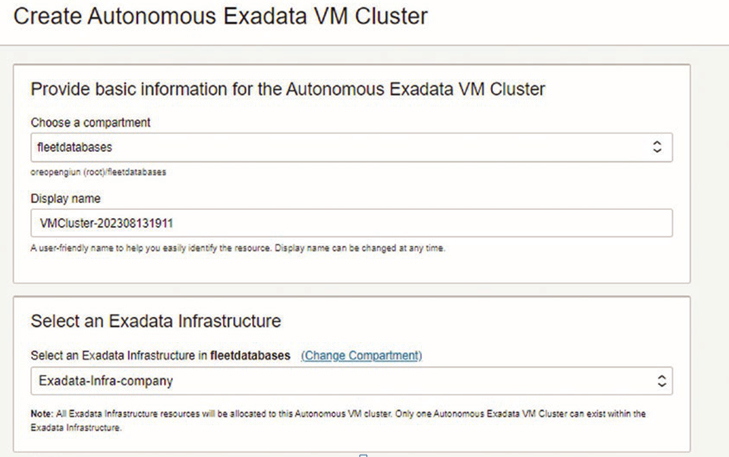
When creating new databases in 23c, you get multitenant CDBs and PDBs. However, there are databases that need to be upgraded to 23c, and many of them can be noncontainer, single-instance databases. This of course is the chance to consolidate and leverage all of the advantages we just discussed, but there are a few steps and choices you have when migrating.
The settings always depend on database size, availability requirements, and backup strategies that are needed. We discussed Data Pump jobs, which can migrate data to a newly built 23c database. Exporting and importing the data will move the data, but there will be an outage when importing the data, and how big the database is matters.
Just as we discussed with the backup and recovery processes, there are strategies for upgrading and migrating and plenty of options. The main things to consider are the following:
• Repeatable process
• Easy way to back out or downgrade
• Database size
• Downtime window
Simplicity is another piece to consider, especially when maintaining a large environment. It is important to have steps to validate the process, execute it, and verify that the migration was successful.
Plug-In Method
Here is an example to walk through the steps to migrate to multitenant.
First, check the compatibility of the database. This will be performed on the source:
SQL> exec dbms_pdb.describe(‘/tmp/salesdb.xml’);
This creates a manifest XML file, with information about services and data files of the database to be migrated.
Next, check the compatibility of the CDB, which is the target:
SQL> set serveroutput on begin if dbms_pdb.check_plug_compatibility(‘/tmp/salesdb.xml’) THEN dbms_output.put_line(‘PDB compatible? ==> Yes’); else dbms_output.put_line(‘PDB compatible? ==> No’); end if; end; /
This will check if there are any issues that will appear when plugging in the database instance to the CDB. There is valuable information in the PDB_PLUG_IN_VIOLATIONS view after running the check_plug_compatibility script. There might be error and warning messages that can be resolved before plugging the database in.
For example, the version might be the same, so you can upgrade first or let the upgrade occur after plugging the database in. Also, there are possible warnings that are informational such as requiring noncdb_to_pdb.sql to run after it is plugged into the CDB.
SQL> select type, message from pdb_plug_in_violations where name=’SALESDB’ and status <> ‘RESOLVED’;
Next, you need to create the manifest file of the source single-instance database. The database will need to be in read-only mode.
Restart the source database in read-only mode:
SQL> shutdown immediate
SQL> startup mount
SQL> alter database open read only;
The manifest file needs to be generated:
SQL> exec dbms_pdb.describe(‘/tmp/salesdb.xml’);
SQL> shutdown immediate;
This is the same command we ran on the source to be able to validate the manifest file, but now the database was in read-only mode.
In the target CDB, the next step to is create the PDB from the manifest file just created:
SQL> create pluggable database salesdb using ‘/tmp/salesdb.xml’ nocopy tempfile reuse;
There are steps that are still needed to complete the migration to a container PDB. Convert to a PDB by running noncdb_to_pdb.sql:
SQL> alter pluggable database salesdb open;
SQL> alter session set container = salesdb;
SQL> @?/rdbms/admin/noncdb_to_pdb.sql
SQL> alter pluggable database salesdb close;
SQL> alter pluggable database salesdb open;
Once again, check any plug-in violations from the target CDB:
SQL> select type, message from pdb_plug_in_violations
where name=’SALESDB’ and status <> ‘RESOLVED’;
Verify that the PDB is open so you can save the state of the PDB to have it set to auto-start:
SQL> select open_mode, restricted from v$pdbs;
SQL> alter pluggable database salesdb save state;
Once you plug the database in, it does not have the ability to revert to a noncontainer, single-instance database.
There are other recoverability options, but it should be considered to be prepared to troubleshoot the issues in the container and gives you another reason to make sure you check those error and warning messages before migrating.
When you plug in a database, you can use AutoUpgrade to upgrade the database with the new CDB. The target CDB is part of the config file, so the database will be upgraded.
Here is the config file:
$ cat db19to23.cfg Upgl.source_home=/u01/app/oracle/product/19 upgl.target_home=/u01/app/oracle/product/23 upgl.sid=salesdbupgl.target_cdb_cdb=cdb23c
Run the autoupgrade command with the config file:
$ java -jar autoupgrade.jar -config db19to23.cfg -mode deploy