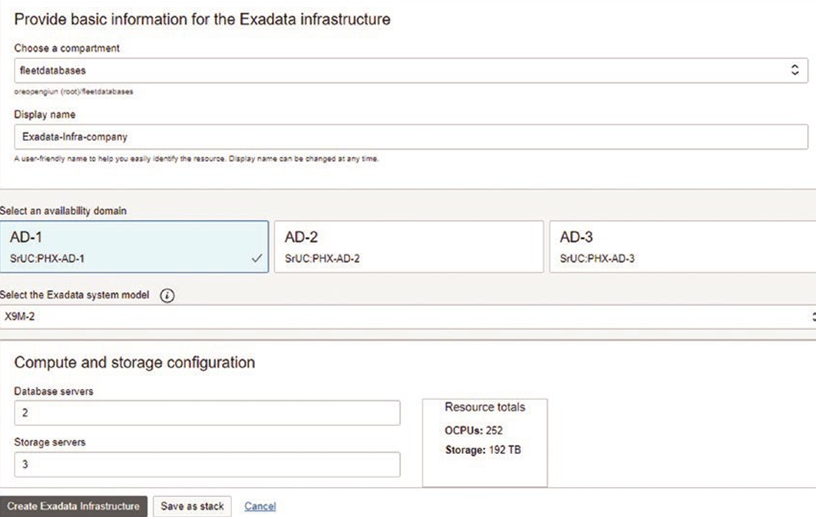
If you use bind variables, then everyone who submits the same exact query that references the same object will use the compiled plan from the pool. You will compile your subroutine once and use it over and over again. This is very efficient and is the way the database intends you to work. Not only will you use fewer resources (a soft parse is much less resource-intensive), but also you will hold latches for less time and need them less frequently. This increases your performance and greatly increases your scalability.
Just to give you a tiny idea of how huge a difference this can make performance-wise, you only need to run a very small test. In this test, we’ll just be inserting some rows into a table; the simple table we will use is
SQL> drop table t purge;
SQL> create table t ( x int );
Table created.
Now we’ll create two very simple stored procedures. They both will insert the numbers 1 through 10,000 into this table; however, the first procedure uses a single SQL statement with a bind variable:
Procedure created.
The second procedure constructs a unique SQL statement for each row to be inserted:
SQL> create or replace procedure proc2 as
Now, the only difference between the two is that one uses a bind variable and the other does not. Both are using dynamic SQL and the logic is otherwise identical. The only difference is the use of a bind variable in the first.
Note For details on runstats and other utilities, see the “Setting Up Your Environment” section at the beginning of this book. You may not observe exactly the same values for CPU or any metric. Differences are caused by different Oracle versions, different operating systems, and different hardware platforms. The idea will be the same, but the exact numbers will undoubtedly be marginally different.
We are ready to evaluate the two approaches, and we’ll use runstats, a simple tool
I’ve developed, to compare the two in detail:
Now, the preceding result clearly shows that based on CPU time (measured in hundredths of seconds), it took significantly longer and significantly more resources to insert 10,000 rows without bind variables than it did with them. In fact, it took more than a magnitude more CPU time to insert the rows without bind variables. For every insert without bind variables, we spent the vast preponderance of the time to execute the statement simply parsing the statement! But it gets worse. When we look at other information, we can see a significant difference in the resources utilized by each approach:
The runstats utility produces a report that shows differences in latch utilization as well as differences in statistics. Here, I asked runstats to print out anything with a difference greater than 9500. You can see that we hard parsed 3 times in the first approach using bind variables and that we hard parsed 10,000 times without bind variables (once for each of the inserts). But that difference in hard parsing is just the tip of the iceberg. You can see here that we used an order of magnitude as many “latches” in the nonbind variable approach as we did with bind variables. That difference might beg the question “What is a latch?”
Let’s answer that question. A latch is a type of lock that is used to serialize access to shared data structures used by Oracle. The shared pool is an example; it’s a big, shared data structure found in the System Global Area (SGA), and this is where Oracle stores parsed, compiled SQL. When you modify anything in this shared structure, you must take care to allow only one process in at a time. (It is very bad if two processes or threads attempt to update the same in-memory data structure simultaneously— corruption would abound.) So, Oracle employs a latching mechanism, a lightweight locking method to serialize access. Don’t be fooled by the word lightweight. Latches are serialization devices, allowing access (to a memory structure) one process at a time. The latches used by the hard parsing implementation are some of the most used latches out there. These include the latches for the shared pool and for the library cache. Those are “big time” latches that people compete for frequently. What all this means is that as we increase the number of users attempting to hard parse statements simultaneously, our performance gets progressively worse over time. The more people parsing, the more people waiting in line to latch the shared pool, the longer the queues, the longer the wait.